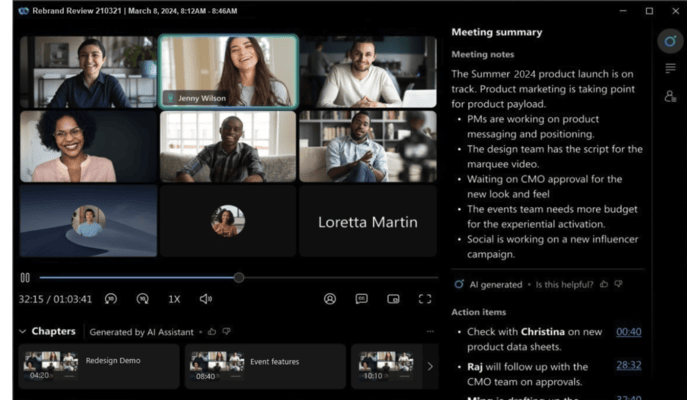
Meeting Summarization and its Auto-Evaluations
In an era of long-context LLM, summarization seems readily available at our fingertips.
However, it is not the case for an hour-long meeting recording, which may contain 10,000+ words with errors inherited from ASR.
We developed a novel LLM subsystem that first chapterizes the meeting into topics, summarizes each topic to form summary bullet points and actionable items,
and then stitches back timestamps for each chapter.
Evaluation of LLM generation quality is a challenging task. To facilitate summary quality assessment for continuous monitoring,
we developed a set of both reference-free and reference-based metrics, utilizing auxiliary deep learning models and LLMs as judges.
This enables continuous monitoring and provides a feedback loop for LLM fine-tuning and model selection.
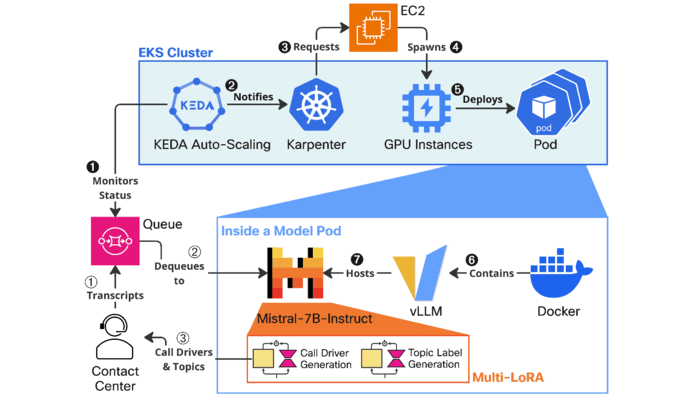
LLM-Based Contact Center Analytics and Cost-Efficient Deployment
Large Language Models have transformed the Contact Center industry,
manifesting in enhanced self-service tools, streamlined administrative processes,
and augmented agent productivity.
This work delineates our system that automates call driver generation, which serves as the foundation
for tasks such as topic modeling, incoming call classification, trend detection, and FAQ generation,
delivering actionable insights for contact center agents and administrators to consume.
We present a cost-efficient LLM system design, with 1) a comprehensive evaluation of proprietary,
open-weight, and fine-tuned models and 2) cost-efficient strategies,
and 3) the corresponding cost analysis when deployed in production environments.
Preprint: Coming Soon.
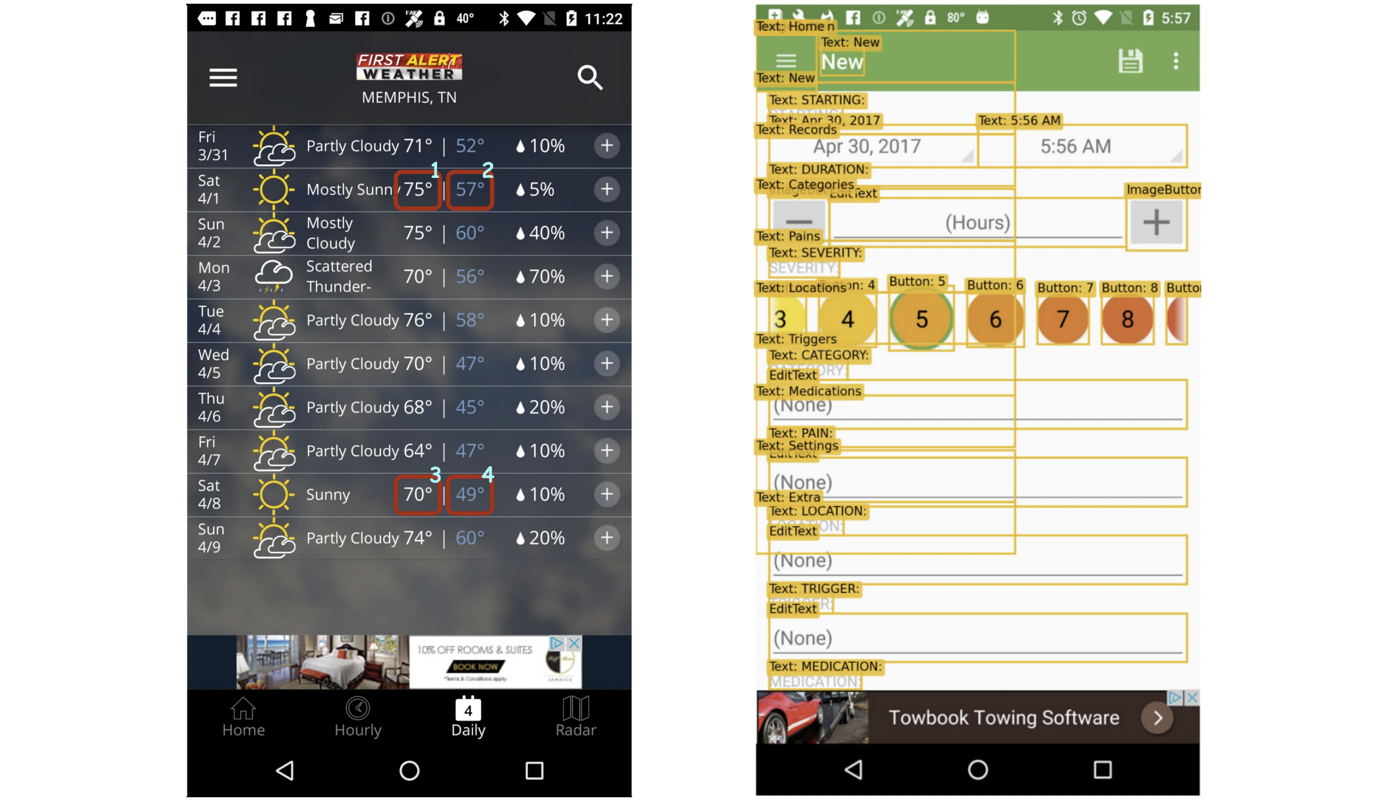
ScreenQA: Question-Answer Pairs Over Mobile App Screenshots
We present a new task and dataset, ScreenQA, for screen content understanding via question
answering. The existing screen datasets are focused either on structure and component-level
understanding, or on a much higher-level composite task such as navigation and task completion.
We bridge this gap by annotating 80,000+ question-answer pairs over the RICO dataset to benchmark
screen reading comprehension capacity.
The challenge of this task lies in three aspects:
1) Screenshots are a natural mixture of text, symbols, and images in a layout. The model is expected
to understand interactions between these modalities.
2) UI elements are not precisely given. Although the structural information such view hierarchies and
DOM trees may be available, they typically exhibit noticeable rendering issues (right of the image).
3) The complete answer may come from multiple parts from the screen (left of the image).
The task requires the model to include all pieces to get a full score.
Accepted to NAACL 2025.
Preprint.
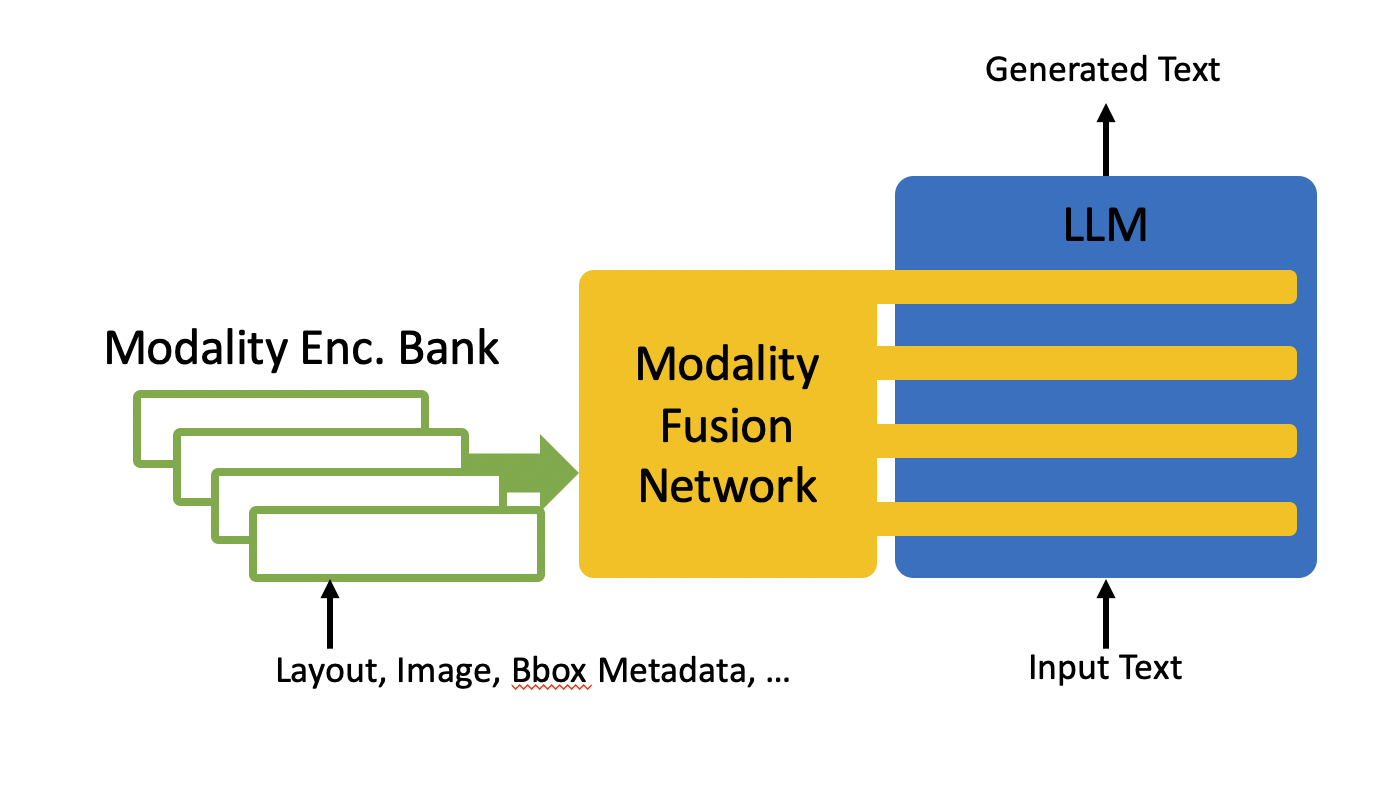
Multimodal LLM for Document and Screen Understanding
Scanned document images and screenshots share a common characteristic: both contain text phrases arranged in a non-sequential manner within image pixels. To build a foundation model that works for various downstream tasks, we need to inject multiple modalities, such as text phrases, coordinates of the phrases, the corresponding image crops, and the overall image pixels, in order to provide comprehensive understanding and representation learning.
To achieve this aim, we integrate various state-of-the-art architectures: From language modeling, we investigate Encoder-Decoder/Decoder-Only LLMs. From document understanding, Attention Bias develops the awareness of 2D layout alignment. From image encoding, we explore ResNet, DETR, Vision Transformer (ViT), and other approaches. From modality fusion, we study Perceiver, Flamingo, Prompt Tuning, and Cross Attention. The goal is simple: to provide the best model that works well for all types of Document and Screen Understanding tasks.

Multi-Span Question Answering
The state-of-the-art closed-domain question answering
problem like
SQuAD expects a single-span answer from the closed-domain context.
However, in a more natural setting, a question typically comes first.
Then the relevant document is retrieved by a search engine to pair up the question
as the context.
In such a case, the answer usually scatters all over the context as multiple phrases.
An example can be seen from the image above.
This is a step forward toward a semi-open-domain question answering system.
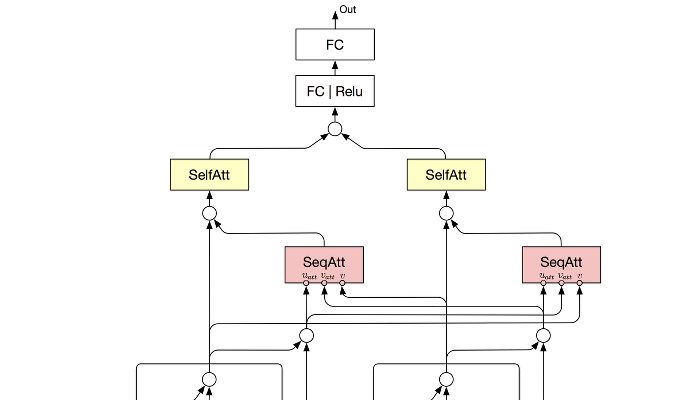
This project utilized BiLSTM with
Co-Attention and Self-Attention mechanisms, implemented in
PyTorch.
Deep Learning for Ranking
Document relevance ranking, recommendation, and potentially click-through rate
prediction can
be all accomplished through NLP deep learning.
The canonical neural network design is to start with a word- and/or character-level embedding,
followed by layers of RNN
and Attention mechanisms that fuse multiple input signals together
(typically query and document), and end with a metric of the ranking loss.
This approach is significant more accurate than traditional information retrieval methods,
such as TFIDF or BM25, at a cost of much higher computational complexity.
How to strive for a balance between these two types of methods is the key for a
practical design.
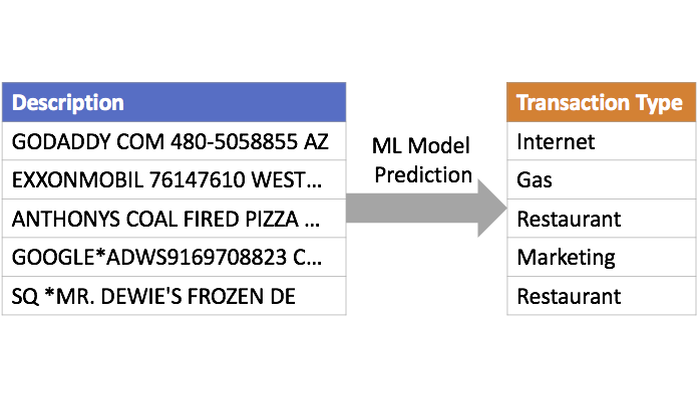
Text Classification for Transaction Data
The text in credit card transaction descriptions are largely ungrammatical,
with scrambled word ordering and inconsistent space delimiters (e.g., whitespace, asterisk,
and/or a mixture of both).
This poses challenges in proper tokenization.
Examples can be seen above.
In this case, RNN or Transformers may be of little help but just computationally expensive.
A better trade-off can be achieved using a traditional NLP method, such as
bag-of-words featurization on letter n-grams, followed by classic multi-class classification methods.
This method is patented here:
Patent.
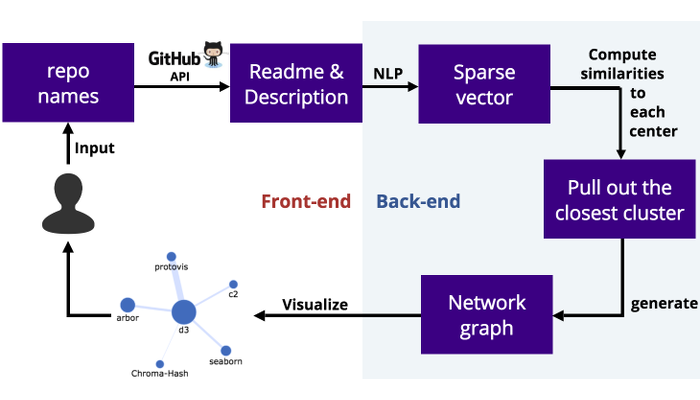
GitHub Repo Recommender System
GitHub is great except for navigating yourself on the site.
Back in 2014 when this project was conducted, the GitHub repo recommendation
functionality left a lot to be desired (it is now improved very much compared to then).
In light of this, I designed and implemented a GitHub recommender system based on
README keyword similarities.
The relevant repos are precomputed and clustered by the affinity propagation method
to enable real-time retrieval upon users' request.
The overall recommender system is implemented in Python and was served
as a web application.
Slides.
GitHub.
Point Cloud Object Recognition
The point cloud image representation has been growing its popularity due to the recent
increases of LIDAR signal applications from the autonomous driving and robotics industry.
To recognize the objects from points directly (without projecting points onto pre-defined grids),
one recent breakthrough is the work
"PointNet,"
which relies on symmetric functions whose computation is independent of
data orders and all points can then be treated as an unordered set.
However, the original work of PointNet does not utilize the proximity information
between points and seems to have room for improvement.
I proposed an augmentation method "super points," a representation of point clusters,
to help the neural net recognize point proximity information.
This improves the prediction accuracy against the ModelNet40 benchmark.
Report.
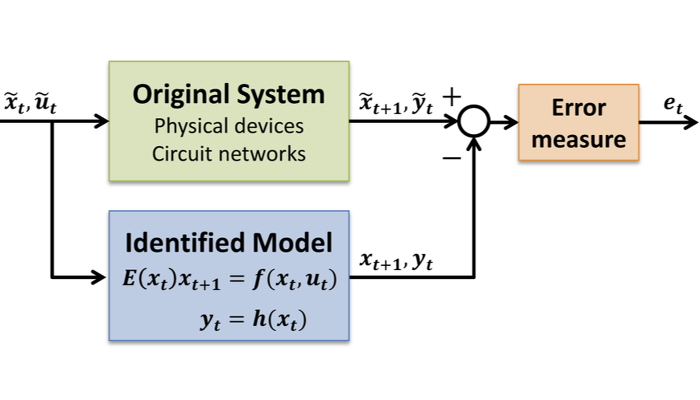
Automated Modeling of Nonlinear Dynamical Systems
This project is to design a black-box learning algorithm for nonlinear
dynamical system modeling, with the aim to enable
hierarchical, bottom-up modeling strategy.
Prior to this work, the existing modeling methods for nonlinear dynamical systems
target only the end-to-end modeling scenario, which implies that
any small changes in one component of the system
requires a whole model retraining.
A more practical approach is to build a model of each component of the system
one at a time and then construct the whole system by composing component models.
However, composing models implicitly creates feedback loops and almost always
unstabilizes the overall system model.
I developed a convexified theoretical criterion such that the composed systems
are numerically stable and implemented a convex optimization program.
This method has been successfully applied to nonlinear circuits,
human arterial networks, and finance time-series stock price prediction.
Thesis.
GitHub.
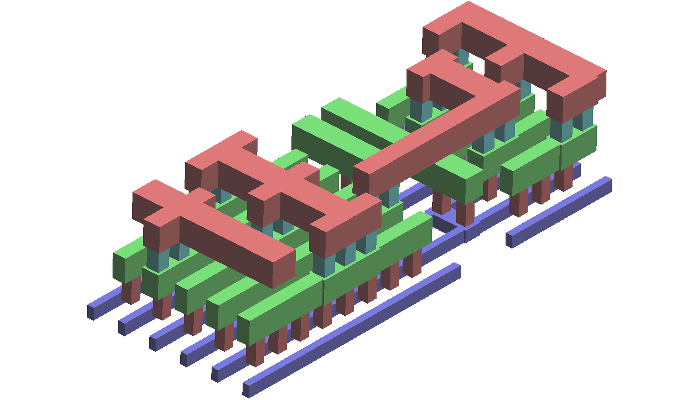
CAPLET: Parallelized Capacitance Extraction Toolkit
CAPLET is an open-source capacitance extraction toolkit that computes field-solver
accurate solutions using our developed ultra parallel-efficient algorithm,
which is built on top of empirical instantiable basis functions
for the boundary element method.
Our freely released software covers the complete extraction flow from GDS2 layout
files to capacitance matrices.
This is, to the best of our knowledge, the first open-source extraction tool that
incorporates geometry algorithms, basis function generation, 3D layout visualization,
and parallelized field solver extraction altogether.
CAPLET provides both intuitive GUI and command line interfaces.
The underlying algorithm is specialized for VLSI interconnects in Manhattan
geometries inside a uniform dielectric material.
Website.
GitHub.